
10 years ago I wrote blog post “PDFiD: False Positives” to talk about false positives generated by my tool pdfid.py.
pdfid.py is a triage tool: it’s essentially a “string search tool”, that looks for certain keywords, without parsing the document’s PDF structure.
One of the keywords it looks for is /JS, that indicates the presence of JavaScript. And since /JS is a short string, it can happen that PDF documents contain that character sequence (/JS) somewhere inside a binary stream, with a totally different meaning. At that moment, it’s not a keyword, but just a byte sequence found inside a binary stream (for example, a JPEG image).
So that’s a false positive, because it is not an indicator for the presence of JavaScript.
10 years ago, I adviced to use pdf-parser to search for those sequences.
From time to time, people still ask me about these false positives, and it’s actually good to write a revisited diary entry about this.
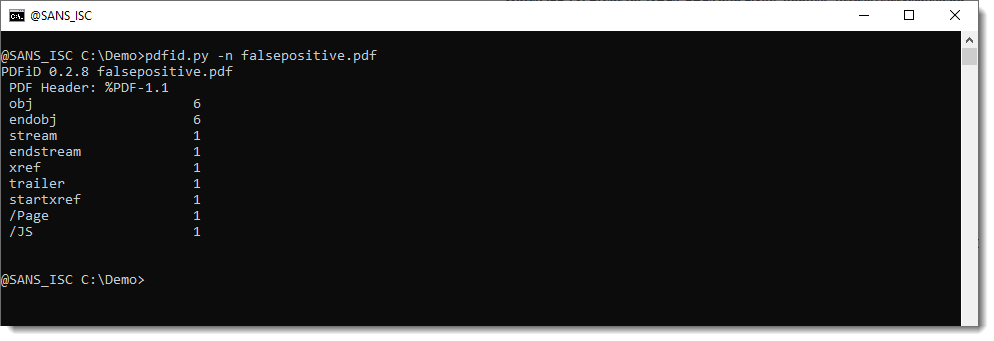
If you have a PDFiD detection for a short string like /JS:
And you can’t find it with pdf-parser.py:
Then use pdf-parser’s option -a to calculate statistics:
If the /JS detection is a false positive, then it will not appear in pdf-parser’s statistics: that’s because pdf-parser is a PDF parser, and can distinguish between keywords found in the right place (/JS inside a dictionary) and the wrong place (/JS inside a binary stream).
Notice that it’s best to use option -a together with -O, because then stream objects (/ObjStm) will also be parsed:
And just for reference, this is how the output of pdfid and pdf-parser looks with true positives:
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com
(c) SANS Internet Storm Center. https://isc.sans.edu Creative Commons Attribution-Noncommercial 3.0 United States License.